







分布式搜索引擎的面试连环炮
业内目前来说事实上的一个标准,就是分布式搜索引擎一般大家都是用ElasticSearch,(原来的话使用的是Solr),但是确实,这两年大家一般都用更加易用的es。
ElasticSearch 和 Solr 底层都是基于Lucene,而Lucene的底层原理是 倒排索引
倒排索引是什么
倒排索引适用于快速的全文检索,一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表
例如:
假设文档集合中包含五个文档,每个文档的内容如下所示,在图中最左端一栏是每个文档对应的编号,我们的任务就是对这个文档集合建立倒排索引
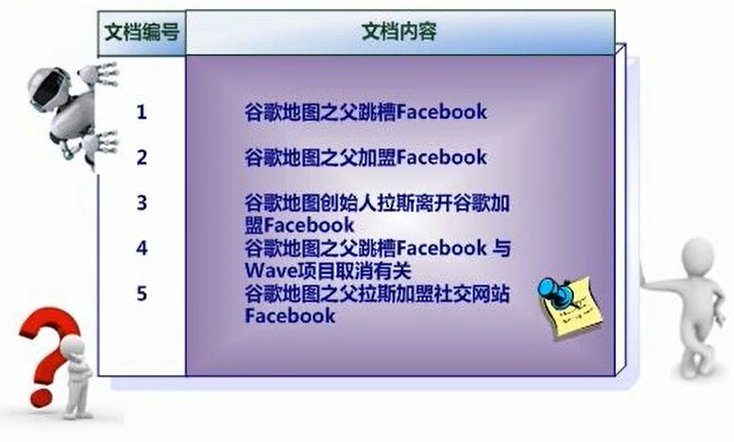
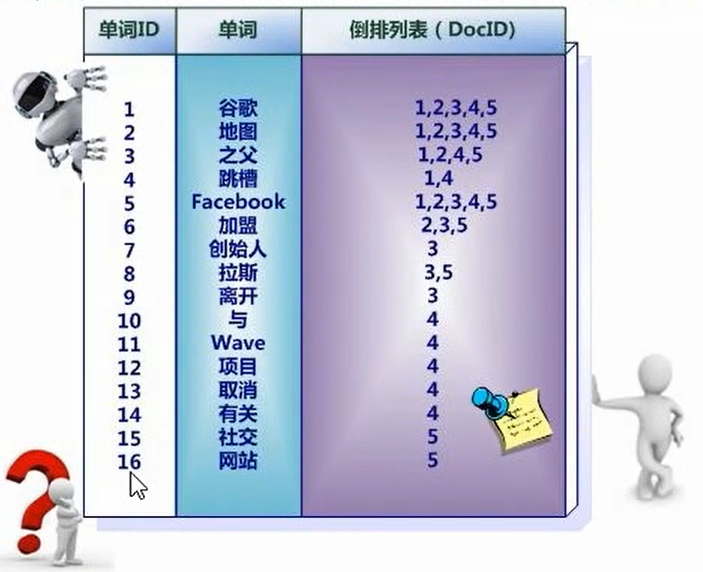
中文和英文等语言不通,单词之间没有明确分割符号,所以首先要用分词系统将文档自动切分成单词序列,这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们就可以得到最简单的倒排索引了
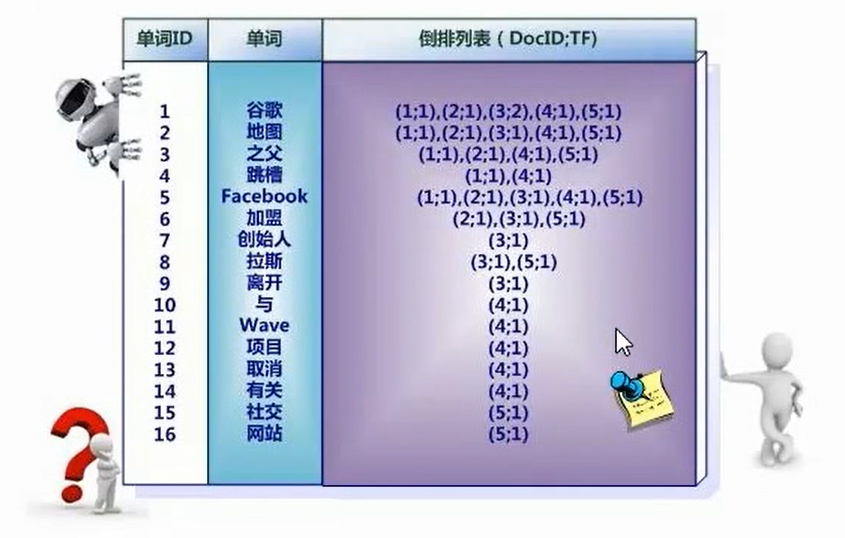
索引系统还可以记录除此之外的更多信息,下图是记录了单词出现的频率(TF)即这个单词在文档中出现的次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以便后续排序时进行分值计算。
倒排列表还可以记录单词在某个文档出现的位置信息
(1, <11>, 1), (2, <7>, 1), (3, <3, 9>, 2)
有了这个索引系统,搜索引擎可以很方便地响应用户的查询,比如用户输入查询词 “Facebook”,搜索系统查找倒排索引,从中可以读出包含这个单词的文档,这些文档就是提供给用户的搜索结果,而利用单词频率信息,文档频率信息即可以对这些候选搜索结果进行排序,计算文档和查询的相似性,按照相似性得分由高到低排序输出,此即为搜索系统的部分内部流程。
中文分词器原理
方法1
分词器的原理本质上是词典分词。在现有内存中初始化一个词典,然后在分词过程中挨个读取字符和字典中的字符相匹配,把文档中所有词语拆分出来的过程。
方法2 字典树
Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
下面一个存放了[大学、大学生、学习、学习机、学生、生气、生活、活着]这个词典的trie树:
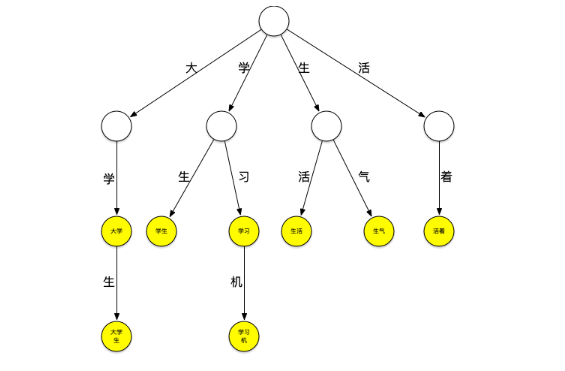
它可以看作是用每个词第n个字做第n到第n+1层节点间路径哈希值的哈希树,每个节点是实际要存放的词。
现在用这个树来进行“大学生活”的匹配。依然从“大”字开始匹配,如下图所示:从根节点开始,沿最左边的路径匹配到了大字,沿着“大”节点可以匹配到“大学”,继续匹配则可以匹配到“大学生”,之后字典中再没有以“大”字开头的词,至此已经匹配到了[大学、大学生]第一轮匹配结束

继续匹配“学”字开头的词,方法同上步,可匹配出[学生]
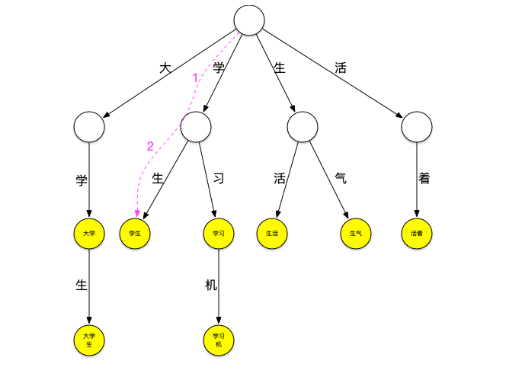
继续匹配“生”和“活”字开头的词,这样“大学生活”在词典中的词全部被查出来。
可以看到,以匹配“大”字开头的词为例,第一种匹配方式需要在词典中查询是否包含“大”、“大学”、“大学”、“大学生活”,共4次查询,而使用trie树查询时当找到“大学生”这个词之后就停止了该轮匹配,减少了匹配的次数,当要匹配的句子越长,这种性能优势就越明显。
失败指针
再来看一下上面的匹配过程,在匹配“大学生”这个词之后,由于词典中不存在其它以“大”字开头的词,本轮结束,将继续匹配以“学”字开头的词,这时,需要再回到根节点继续匹配,如果这个时候“大学生”节点有个指针可以直指向“学生”节点,就可以减少一次查询,类似地,当匹配完“学生”之后如果“学生”节点有个指针可以指向“生活”节点,就又可以减少一次查询。这种当下一层节点无法匹配需要进行跳转的指针就是失败指针,创建好失败指针的树看起来如下图:
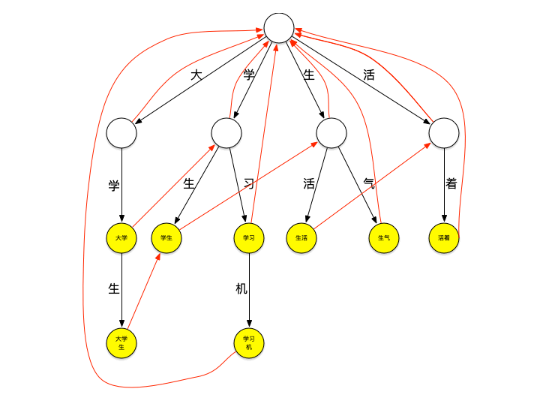
图上红色的线就是失败指针,指向的是当下层节点无法匹配时应该跳转到哪个节点继续进行匹配
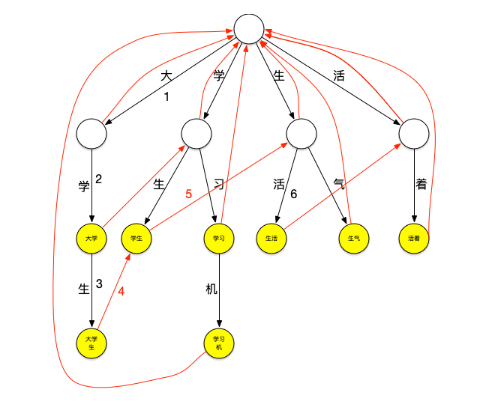
失败指针的创建过程通常为:
-
创建好trie树。
-
BFS每一个节点(不能使用DFS,因为每一层节点的失败指针在创建时要确保上一层节点的失败指针全部创建完成)。
-
根节点的子节点的失败指针指向根节点。
-
其它节点查找其父节点的失败指针指向的节点的子节点是否有和该节点字相同的节点,如果有则失败指针指向该节点,如果没有则重复刚才的过程直至找到字相同的节点或根节点。
查询过程如下:
ES的分布式架构原理能说一下么?
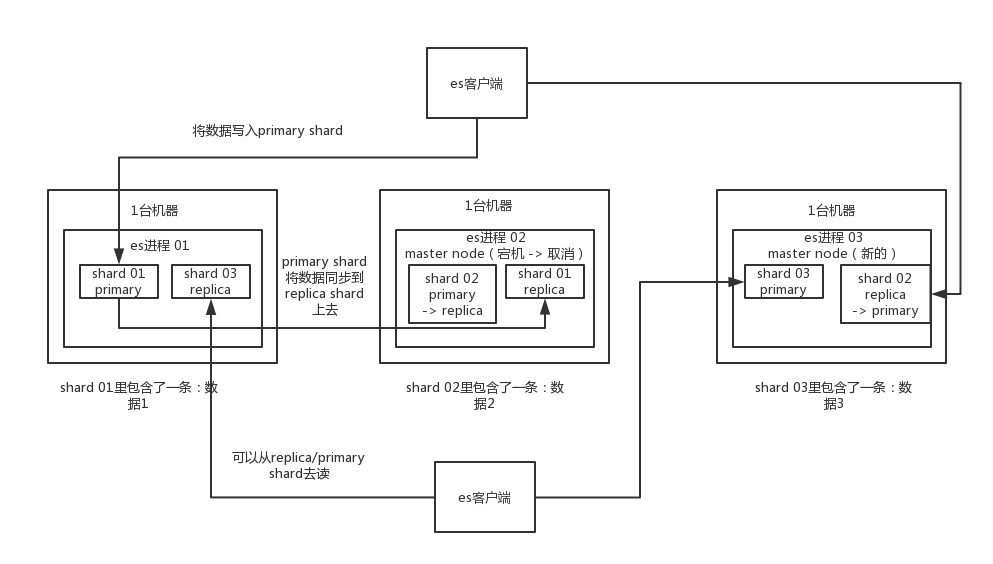
elasticsearch设计的理念就是分布式搜索引擎,底层其实还是基于lucene的。
核心思想就是在多台机器上启动多个es进程实例,组成了一个es集群。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1308
1308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









