









微信搜索【程序员囧辉】,关注这个坚持分享技术干货的程序员。
前言
在 Java 后端的面试中,redis 应该是目前所有框架/中间件中被问到频率最高的,至少也是之一。
就算把范围扩大到整个 Java 后端面试知识体系,面试中出现频率比 redis 高的也不多,可能就那么几个:HashMap、线程池之类的。
由于比较重要,知识点也比较多,所以这边预计分为多篇来呈现。
除了本文之外,主要还有两个方向,一个围绕高可用,主要是持久化、主从复制、哨兵、集群模式等。
另一个围绕 redis 的实践,主要是分布式锁、缓存穿透、缓存雪崩、缓存击穿等。
正文
redis 是单线程还是多线程
这个问题应该已经看到过无数次了,最近 redis 6 出来之后又被翻出来了。
redis 4.0 之前,redis 是完全单线程的。
redis 4.0 时,redis 引入了多线程,但是额外的线程只是用于后台处理,例如:删除对象,核心流程还是完全单线程的。这也是为什么有些人说 4.0 是单线程的,因为他们指的是核心流程是单线程的。
这边的核心流程指的是 redis 正常处理客户端请求的流程,通常包括:接收命令、解析命令、执行命令、返回结果等。
而在最近,redis 6.0 版本又一次引入了多线程概念,与 4.0 不同的是,这次的多线程会涉及到上述的核心流程。
redis 6.0 中,多线程主要用于网络 I/O 阶段,也就是接收命令和写回结果阶段,而在执行命令阶段,还是由单线程串行执行。由于执行时还是串行,因此无需考虑并发安全问题。
值得注意的时,redis 中的多线程组不会同时存在“读”和“写”,这个多线程组只会同时“读”或者同时“写”。
redis 6.0 加入多线程 I/O 之后,处理命令的核心流程如下:
1、当有读事件到来时,主线程将该客户端连接放到全局等待读队列
2、读取数据:1)主线程将等待读队列的客户端连接通过轮询调度算法分配给 I/O 线程处理;2)同时主线程也会自己负责处理一个客户端连接的读事件;3)当主线程处理完该连接的读事件后,会自旋等待所有 I/O 线程处理完毕
3、命令执行:主线程按照事件被加入全局等待读队列的顺序(这边保证了执行顺序是正确的),串行执行客户端命令,然后将客户端连接放到全局等待写队列
4、写回结果:跟等待读队列处理类似,主线程将等待写队列的客户端连接使用轮询调度算法分配给 I/O 线程处理,同时自己也会处理一个,当主线程处理完毕后,会自旋等待所有 I/O 线程处理完毕,最后清空队列。
大致流程图如下:
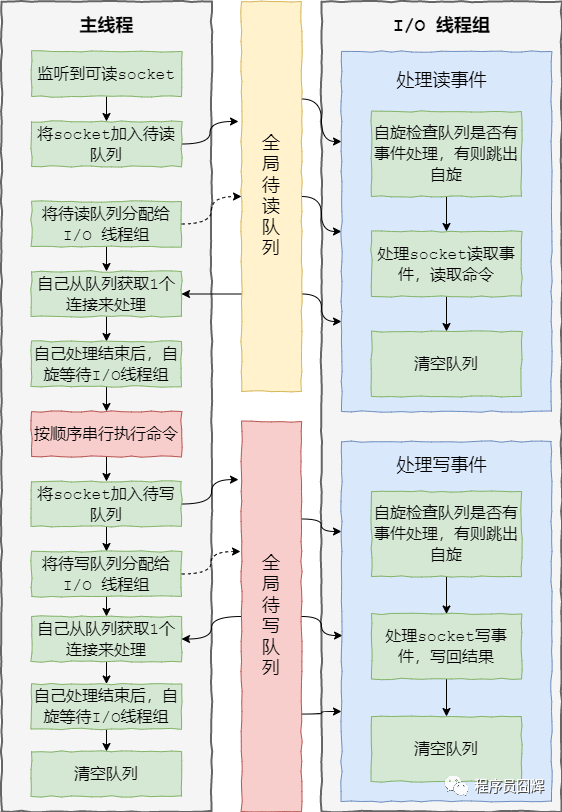
相关源码在 networking.c,核心的方法是:
IOThreadMain、handleClientsWithPendingReadsUsingThreads、
handleClientsWithPendingWritesUsingThreads
为什么 redis 是单线程
在 redis 6.0 之前,redis 的核心操作是单线程的。
因为 redis 是完全基于内存操作的,通常情况下CPU不会是redis的瓶颈,redis 的瓶颈最有可能是机器内存的大小或者网络带宽。
既然CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了,因为如果使用多线程的话会更复杂,同时需要引入上下文切换、加锁等等,会带来额外的性能消耗。
而随着近些年互联网的不断发展,大家对于缓存的性能要求也越来越高了,因此 redis 也开始在逐渐往多线程方向发展。
最近的 6.0 版本就对核心流程引入了多线程,主要用于解决 redis 在网络 I/O 上的性能瓶颈。而对于核心的命令执行阶段,目前还是单线程的。
redis 为什么使用单进程、单线程也很快
1、基于内存的操作
2、使用了 I/O 多路复用模型,select、epoll 等,基于 reactor 模式开发了自己的网络事件处理器
3、单线程可以避免不必要的上下文切换和竞争条件,减少了这方面的性能消耗。
4、以上这三点是 redis 性能高的主要原因,其他的还有一些小优化,例如:对数据结构进行了优化,简单动态字符串、压缩列表等。
项目中使用的 redis 版本
这个问题是我在面试某大厂真实碰到过的,所以大家平时在使用中间件和框架时可以留意下自使用的版本。
下图是从 redis 官方 github 截的图,包含了 redis 2.2 之后的所有版本,目前常用的应该是:3.2.*、4.0.*、5.0.*。
redis 在项目中的使用场景
缓存、分布式锁、排行榜(zset)、计数(incrby)、消息队列(stream)、地理位置(geo)、访客统计(hyperloglog)等。
redis常见的数据结构
常见的5种:
-
String:字符串,最基础的数据类型。
-
List:列表。
-
Hash:哈希对象。
-
Set:集合。
-
Sorted Set:有序集合,Set 的基础上加了个分值。
高级的4种:
-
HyperLogLog:通常用于基数统计。使用少量固定大小的内存,来统计集合中唯一元素的数量。统计结果不是精确值,而是一个带有0.81%标准差(standard error)的近似值。所以,HyperLogLog适用于一些对于统计结果精确度要求不是特别高的场景,例如网站的UV统计。
-
Geo:redis 3.2 版本的新特性。可以将用户给定的地理位置信息储存起来, 并对这些信息进行操作:获取2个位置的距离、根据给定地理位置坐标获取指定范围内的地理位置集合。
-
Bitmap:位图。
-
Stream:主要用于消息队列,类似于 kafka,可以认为是 pub/sub 的改进版。提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Redis的字符串(SDS)和C语言的字符串区别
| C字符串 | SDS |
| 获取字符串长度的复杂度为O(N) | 获取字符串长度的复杂度为O(1) |
| API是不安全的,可能会造成缓冲区溢出 | API是安全的,不会造成缓冲区溢出 |
| 修改字符串长度N次必然需要执行N次内存重分配 | 修改字符串长度N次最多需要执行N次内存重分配 |
| 只能保存文本数据 | 可以保存文本数据或者二进制数据 |
| 可以使用所有的<string.h>库中的函数 | 可以使用一部分<string.h>库中的函数 |
Sorted Set底层数据结构
Sorted Set(有序集合)当前有两种编码:ziplist、skiplist
ziplist:使用压缩列表实现,当保存的元素长度都小于64字节,同时数量小于128时,使用该编码方式,否则会使用 skiplist。这两个参数可以通过 zset-max-ziplist-entries、zset-max-ziplist-value 来自定义修改。

skiplist:zset实现,一个zset同时包含一个字典(dict)和一个跳跃表(zskiplist)
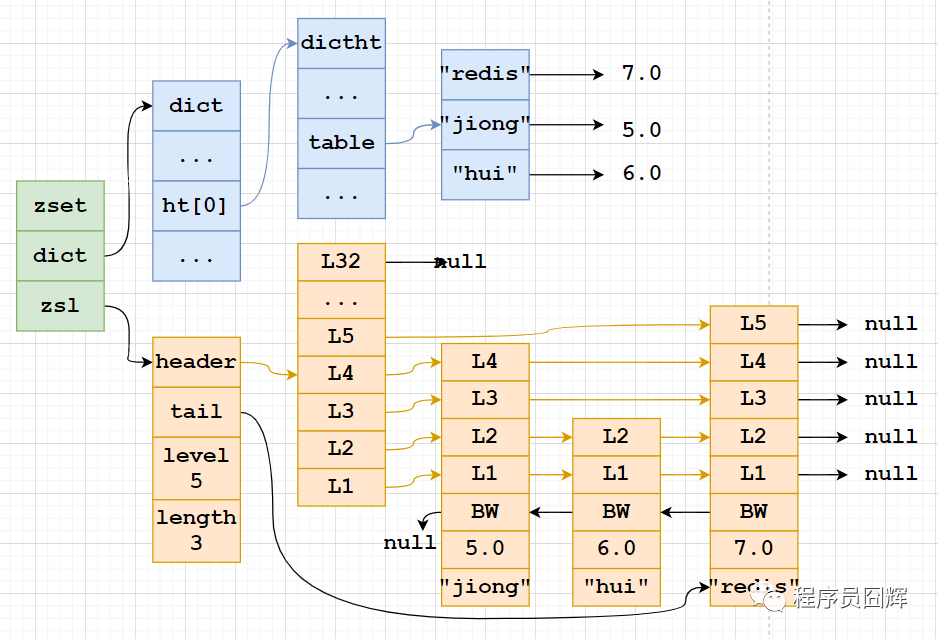
Sorted Set为什么同时使用字典和跳跃表?
主要是为了性能。
单独使用字典:在执行范围型操作,比如zrank、zrange,字典需要进行排序,至少需要O(NlogN)的时间复杂度及额外O(N)的内存空间。
单独使用跳跃表:根据成员查找分值操作的复杂度从O(1)上升为O(logN)。
Sorted Set为什么使用跳跃表,而不是红黑树?
1)跳表的性能和红黑树差不多。
2)跳表更容易实现和调试。
网上有同学说是因为作者不会红黑树,我觉得挺有可能的。

Hash 对象底层结构
Hash 对象当前有两种编码:ziplist、hashtable
ziplist:使用压缩列表实现,每当有新的键值对要加入到哈希对象时,程序会先将保存了键的节点推入到压缩列表的表尾,然后再将保存了值的节点推入到压缩列表表尾。
因此:1)保存了同一键值对的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后;2)先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后来添加的会被放在表尾方向。

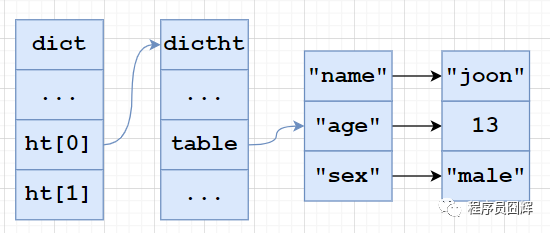
hashtable:使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典键值来保存,跟 java 中的 HashMap 类似。
Hash 对象的扩容流程
hash 对象在扩容时使用了一种叫“渐进式 rehash”的方式,步骤如下:
1、计算新表 size、掩码,为新表 ht[1] 分配空间,让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
2、将 rehash 索引计数器变量 rehashidx 的值设置为0,表示 rehash 正式开始。
3、在 rehash 进行期间,每次对字典执行添加、删除、査找、更新操作时,程序除了执行指定的操作以外,还会触发额外的 rehash 操作,在源码中的 _dictRehashStep 方法。
_dictRehashStep:从名字也可以看出来,大意是 rehash 一步,也就是 rehash 一个索引位置。
该方法会从 ht[0] 表的 rehashidx 索引位置上开始向后查找,找到第一个不为空的索引位置,将该索引位置的所有节点 rehash 到 ht[1],当本次 rehash 工作完成之后,将 ht[0] 的 rehashidx 位置清空,同时将 rehashidx 属性的值加一。
4、将 rehash 分摊到每个操作上确实是非常妙的方式,但是万一此时服务器比较空闲,一直没有什么操作,难道 redis 要一直持有两个哈希表吗?
答案当然不是的。我们知道,redis 除了文件事件外,还有时间事件,redis 会定期触发时间事件,这些时间事件用于执行一些后台操作,其中就包含 rehash 操作:当 redis 发现有字典正在进行 rehash 操作时,会花费1毫秒的时间,一起帮忙进行 rehash。
5、随着操作的不断执行,最终在某个时间点上,ht[0] 的所有键值对都会被 rehash 至 ht[1],此时 rehash 流程完成,会执行最后的清理工作:释放 ht[0] 的空间、将 ht[0] 指向 ht[1]、重置 ht[1]、重置 rehashidx 的值为 -1。
相关源码在 dict.c,核心方法是:dictExpand、dictRehashMilliseconds、dictRehash、dictFind、
渐进式 rehash 的优点
渐进式 rehash 的好处在于它采取分而治之的方式,将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式 rehash 而带来的庞大计算量。
在进行渐进式 rehash 的过程中,字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间,字典的删除、査找、更新等操作会在两个哈希表上进行。例如,要在字典里面査找一个键的话,程序会先在 ht[0] 里面进行査找,如果没找到的话,就会继续到 ht[1] 里面进行査找,诸如此类。
另外,在渐进式 rehash 执行期间,新增的键值对会被直接保存到 ht[1], ht[0] 不再进行任何添加操作,这样就保证了 ht[0] 包含的键值对数量会只减不增,并随着 rehash 操作的执行而最终变成空表。
rehash 流程在数据量大的时候会有什么问题吗
1、扩容期开始时,会先给 ht[1] 申请空间,所以在整个扩容期间,会同时存在 ht[0] 和 ht[1],会占用额外的空间。
2、扩容期间同时存在 ht[0] 和 ht[1],查找、删除、更新等操作有概率需要操作两张表,耗时会增加。
3、redis 在内存使用接近 maxmemory 并且有设置驱逐策略的情况下,出现 rehash 会使得内存占用超过 maxmemory,触发驱逐淘汰操作,导致 master/slave 均有有大量的 key 被驱逐淘汰,从而出现 master/slave 主从不一致。
Redis的事件处理器
redis 基于 reactor 模式开发了自己的网络事件处理器,由4个部分组成:套接字、I/O 多路复用程序、文件事件分派器(dispatcher)、以及事件处理器。
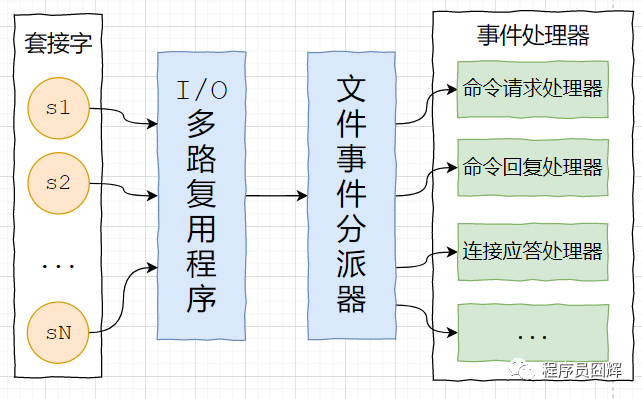
套接字:socket 连接,也就是客户端连接。当一个套接字准备好执行连接、写入、读取、关闭等操作时, 就会产生一个相应的文件事件。因为一个服务器通常会连接多个套接字, 所以多个文件事件有可能会并发地出现。
I/O 多路复用程序:提供 select、epoll、evport、kqueue 的实现,会根据当前系统自动选择最佳的方式。负责监听多个套接字,当套接字产生事件时,会向文件事件分派器传送那些产生了事件的套接字。
当多个文件事件并发出现时, I/O 多路复用程序会将所有产生事件的套接字都放到一个队列里面,然后通过这个队列,以有序、同步、每次一个套接字的方式向文件事件分派器传送套接字:当上一个套接字产生的事件被处理完毕之后,才会继续传送下一个套接字。
文件事件分派器:接收 I/O 多路复用程序传来的套接字, 并根据套接字产生的事件的类型, 调用相应的事件处理器。
事件处理器:事件处理器就是一个个函数, 定义了某个事件发生时, 服务器应该执行的动作。例如:建立连接、命令查询、命令写入、连接关闭等等。
Redis 删除过期键的策略(缓存失效策略、数据过期策略)
定时删除:在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除操作。对内存最友好,对 CPU 时间最不友好。
惰性删除:放任键过期不管,但是每次获取键时,都检査键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。对 CPU 时间最优化,对内存最不友好。
定期删除:每隔一段时间,默认100ms,程序就对数据库进行一次检査,删除里面的过期键。至 于要删除多少过期键,以及要检査多少个数据库,则由算法决定。前两种策略的折中,对 CPU 时间和内存的友好程度较平衡。
Redis 使用惰性删除和定期删除。
Redis 的内存驱逐(淘汰)策略
当 redis 的内存空间(maxmemory 参数配置)已经用满时,redis 将根据配置的驱逐策略(maxmemory-policy 参数配置),进行相应的动作。
当前 redis 的淘汰策略有以下8种。
noeviction:默认策略,不淘汰任何 key,直接返回错误
allkeys-lru:在所有的 key 中,使用 LRU 算法淘汰部分 key
allkeys-lfu:在所有的 key 中,使用 LFU 算法淘汰部分 key
allkeys-random:在所有的 key 中,随机淘汰部分 key
volatile-lru:在设置了过期时间的 key 中,使用 LRU 算法淘汰部分 key
volatile-lfu:在设置了过期时间的 key 中,使用 LFU 算法淘汰部分 key
volatile-random:在设置了过期时间的 key 中,随机淘汰部分 key
volatile-ttl:在设置了过期时间的 key 中,挑选 TTL(time to live,剩余时间)短的 key 淘汰
最后
金三银四的季节,相信有不少同学正准备跳槽。
我将我最近的原创的文章进行了汇总:原创文章汇总,其中有不少面试高频题目解析,很多都是我自己在面试大厂时遇到的,我在对每个题目解析时都会按较高的标准进行深入探讨,可能只看一遍并不能完全明白,但是相信反复阅读,定能有所收获。
原创不易,如果你觉得本文写的还不错,对你有帮助,请通过【点赞】让我知道,支持我写出更好的文章。















 1218
1218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











