







Redis的面试连环炮
面试题
- Redis和Memcache有什么区别
- Redis的线程模型是什么?
- Redis的数据类型及应用场景?
- 为什么单线程的Redis比多线程的Memcache的效率要高?
- 为什么Redis是单线程但是还可以支撑高并发?
- Redis如何通过读写分离来承受百万的QPS
- Redis的持久化策略有哪些?AOF和RDB各有什么优缺点
- Redis的过期策略以及LRU算法
- 如何保证Redis的高并发和高可用?
- redis的主从复制原理能介绍一下么?
- redis的哨兵原理能介绍一下么?
- Redis主备切换的数据丢失问题:异步复制、集群脑裂
- Redis哨兵的底层原理
剖析
Redis最基本的一个内部原理和特点就是NIO异步的单线程工作模型。Memcache是早些年个大互联网公司常用的缓存方案,但是现在近几年都是使用的redis,没有什么公司使用Memcache了。
注意:Redis中单个Value的大小最大为512MB,redis的key和string类型value限制均为512MB
Redis和Memcache的区别
从Redis作者给出的几个比较
- Redis拥有更多的数据结构
- Redis相比Memcache来说,拥有更多的数据结构和支持更丰富的数据操作,通常在Memcache里,你需要将数据拿到客户端来进行类似的修改,在set进去。这就大大增加了网络IO的次数和体积,在Redis中,这些复杂的操作通常和一般的set/get一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么Redis是不错的选择
- Redis内存利用率对比
- 使用简单的key-value存储的话,Memcache的内存利用率更高,而Redis采用Hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcache
- 性能对比
- 由于Redis只使用了单核,而Memcache可以使用多核,所以平均每核上Redis在存储小数据比Memcache性能更高,而在100K以上的数据中,Memcache性能更高,虽然Redis最近也在存储大数据的性能上进行优化,但是比起Memcache还有略有逊色。
- 集群模式
- Memcache没有原生的集群模式,需要依赖客户端来实现往集群中分片写入数据,但是Redis目前是原生支持cluster模式的。
Redis都有哪些数据类型,及使用场景
-
String
- 最基本的类型,就和普通的set 和 get,做简单的key - value 存储
-
Hash
- 这个是 类似于Map的一种结构,就是一半可以将结构化数据,比如对象(前提是这个对象没有嵌套其它对象)给缓存在redis中,每次读写redis缓存的时候,可以操作hash里面的某个字段
key=150 value={ "id": 150, "name": "张三", "age": 20, }- Hash类的数据结构,主要用来存放一些对象,把一些简单的对象给缓存起来,后续操作的时候,你可以直接仅仅修改这个对象中某个字段的值。
-
List
- 有序列表,可以通过list存储一些列表型的数据结构,类似粉丝列表,文章的评论列表之类的东西。
- 可以通过lrange命令,从某个元素开始读取多少个元素,可以基于list实现分页查询,基于Redis实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就是一页一页走。
- 可以制作一个简单的消息队列,从list头插入,从list 的尾巴取出
-
Set
- 无序列表,自动去重
- 直接基于Set将系统中需要去重的数据丢进去,如果你需要对一些数据进行快速的全局去重,就可以使用基于JVM内存里的HashSet进行去重,但是如果你的某个系统部署在多台机器上的话,只有使用Redis进行全局的Set去重
- 可以基于set玩儿交集、并集、差集的操作,比如交集吧,可以把两个人的粉丝列表整一个交集,看看俩人的共同好友是谁?把两个大v的粉丝都放在两个set中,对两个set做交集
-
Sort Set
-
排序的set,去重但是可以排序,写进去的时候给一个分数,自动根据分数排序,这个可以玩儿很多的花样,最大的特点是有个分数可以自定义排序规则
-
比如说你要是想根据时间对数据排序,那么可以写入进去的时候用某个时间作为分数,人家自动给你按照时间排序了
-
排行榜:将每个用户以及其对应的什么分数写入进去,zadd board score username,接着zrevrange board 0 99,就可以获取排名前100的用户;zrank board username,可以看到用户在排行榜里的排名
-
zadd board 85 zhangsan
zadd board 72 wangwu
zadd board 96 lisi
zadd board 62 zhaoliu
96 lisi
85 zhangsan
72 wangwu
62 zhaoliu
zrevrange board 0 3
获取排名前3的用户
96 lisi
85 zhangsan
72 wangwu
zrank board zhaoliu
Redis持久化对于生产环境的意义
故障发生时候会怎么样?
如何应对故障的发生?
Redis持久化的意义
Redis持久化的意义,在于故障恢复,也属于高可用的一个环节。例如
当存放在内存中数据,会因为Redis的突然挂掉,而导致数据丢失
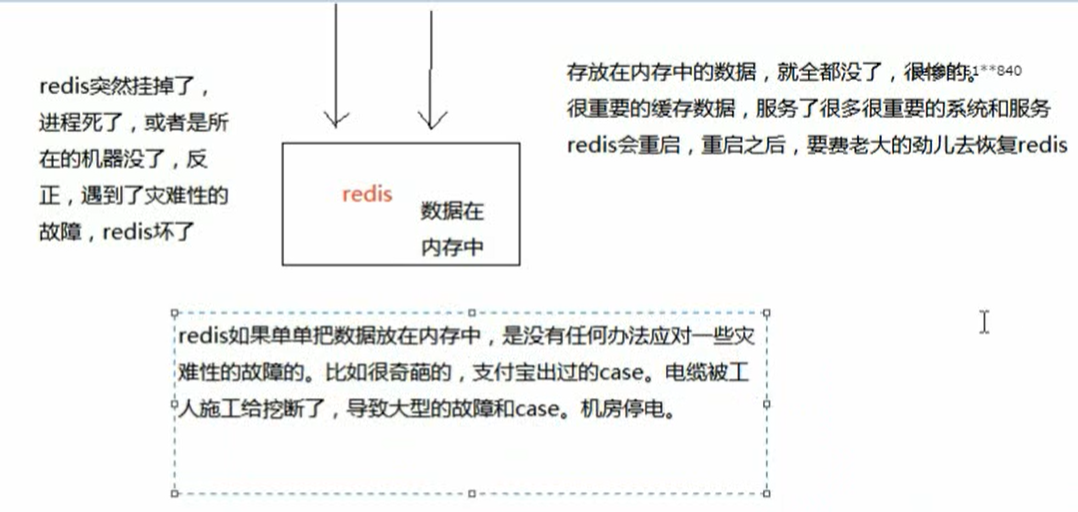
Redis的持久化,就是将内存中的数据,持久化到磁盘上中,然后将磁盘上的数据放到阿里云ODPS中

通过持久化将数据存储在磁盘中,然后定期比如说同步和备份到一些云存储服务上去。
Redis中的RDB和AOF两种持久化机制
当出现Redis宕机时,我们需要做的是重启redis,尽快让他对外提供服务,缓存全部无法命中,在redis里根本找不到数据,这时候就会出现缓存雪崩的问题。所有的请求,没有在Redis中命中,就会去MySQL数据库这种数据源头中找,一下子MySQL无法承受高并发,那么系统将直接宕机。这个时候MySQL宕机,因为没办法从MySQL中将缓存恢复到Redis中,因为Redis中的数据是从MySQL中来的。
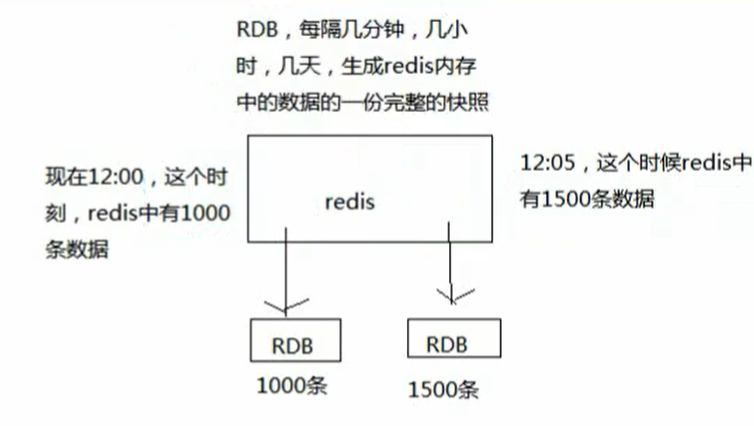
RDB持久化机制
简单来说RDB:就是将Redis中的数据,每个一段时间,进行数据持久化
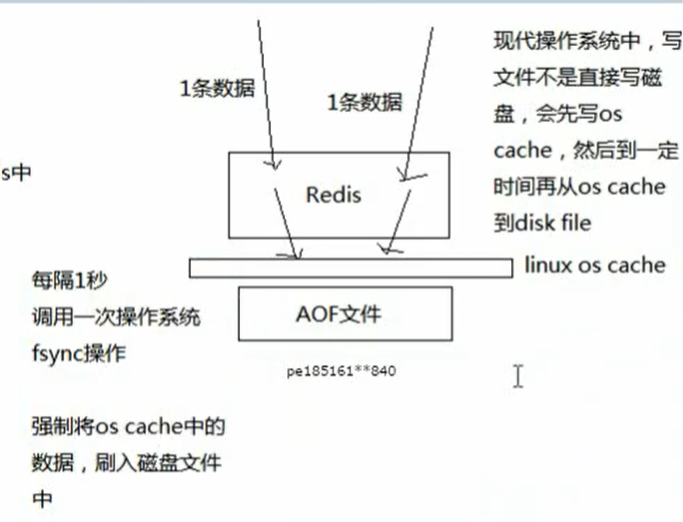
AOF持久化机制
Redis将内存中的数据,存放到一个AOF文件中,但是因为Redis只会写一个AOF文件,因此这个AOF文件会越来越大。
AOF机制对每条写入命令作为日志,以append-only的模式写入一个日志文件中,在Redis重启的时候,可以通过回放AOF日志中的写入指令来重新构建整个数据集。
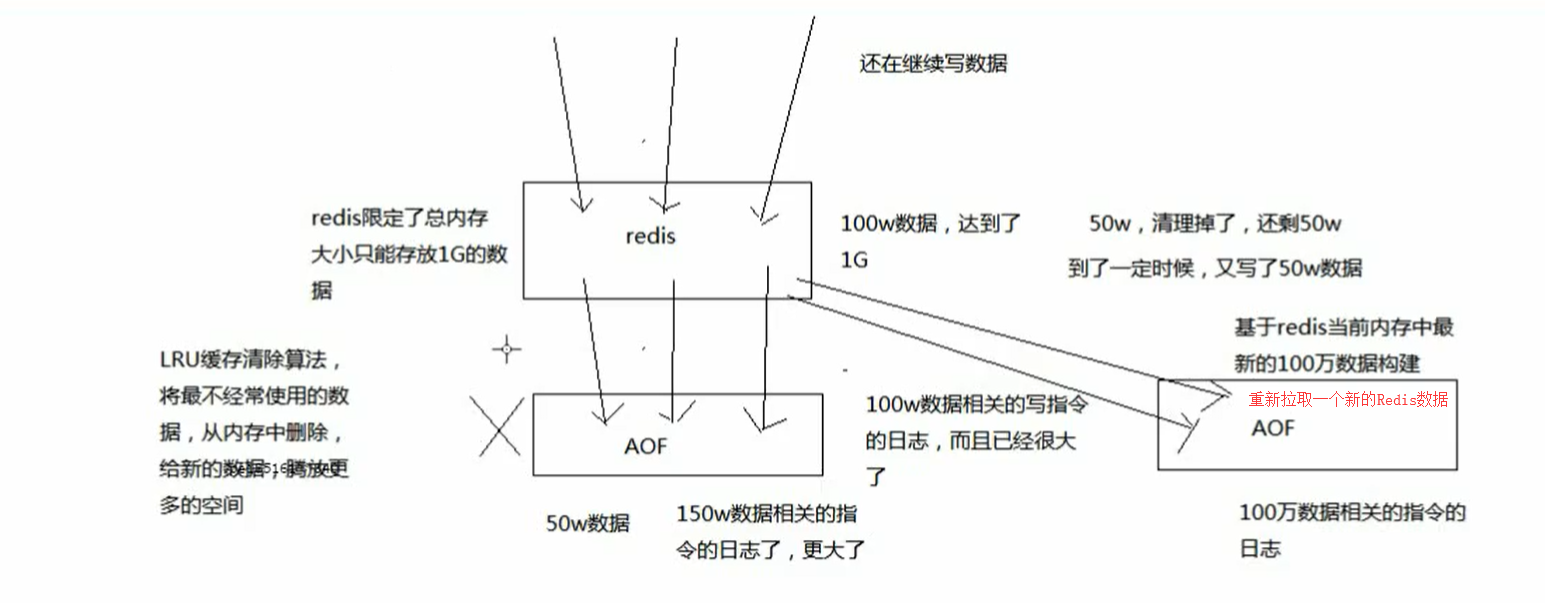
因为Redis中的数据是有一定限量的,不可能说Redis内存中的数据不限量增长,进而导致AOF无限量增长。
内存大小是一定的,到一定时候,Redis就会用缓存淘汰算法,LRU,自动将一部分数据从内存中给清除。
AOF,是存放每条写命令的,所以会不断的膨胀,当大到一定的时候,AOF做rewrite操作。
AOF rewrite操作,就会基于当时redis内存中的数据,来重新构造一个更小的AOF文件,然后将旧的膨胀的很大的文件给删了。
如果我们想要Redis仅仅作为纯内存的缓存来使用,那么可以禁止RDB和AOF所有的持久化机制
通过AOF和RDB,都可以将Redis内存中的数据给持久化到磁盘上面来,然后可以将这些数据备份到其它地方去,例如阿里云的OOS。
如果Redis挂了,服务器上的内存和磁盘上的数据都丢了,可以从云服务上拷贝回来之前的数据,放到指定的目录下,然后重新启动Redis,Redis就会自动根据持久化数据文件,去恢复内存中的数据,继续对外提供服务。
如果同时使用RDB和AOF两种持久化机制,那么在Redis重启的时候,会使用AOF来重新构建数据,因为AOF中的数据更加完整。
RDB持久化机制的优点
- RDB会生成多个数据文件,每个数据文件都代表了某个时刻中Redis的数据,这种多个数据文件的方式,非常适合做冷备份,可以将这种完整的数据文件发送到一些远程的安全存储上去,例如阿里云ODPS分布式存储上,以预定好的备份策略来定期备份Redis中的数据
- RDB也可以做冷备份,生成多个文件,每个文件代表了某个时刻的完整的数据快照
- AOF也可以做冷备,只有一个文件,但是你可以每隔一段时间,去copy一份文件出来
- RDB做冷备份的优势在于,可以由Redis去控制固定时长生成快照文件的事情,比较方便。AOF还需要自己写一些脚本去做这个事情,各种定时。
- RDB对Redis对外提供的读写服务,影响非常小,可以让Redis保持高性能,因为Redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可。
- RDB每次写都是些Redis内存的,只
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









