







目录
6. 数据库索引的原理,为什么要用 B+树,为什么不用二叉树?
8. limit 1000000 加载很慢的话,你是怎么解决的呢?
10. 事务的隔离级别有哪些?MySQL的默认隔离级别是什么?
11. SQL优化的一般步骤是什么,怎么看执行计划(explain),如何理解其中各个字段的含义。
16. 数据库中间件了解过吗,sharding jdbc,mycat?
22. 一条sql执行过长的时间,你如何优化,从哪些方面入手?
34. B树和B+树的区别,数据库为什么使用B+树而不是B树?
36. B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据?
1. MySQL 索引使用有哪些注意事项呢?
索引哪些情况会失效
-
查询条件包含or,可能导致索引失效
-
如何字段类型是字符串,where时一定用引号括起来,否则索引失效
-
like通配符可能导致索引失效。
-
联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
-
在索引列上使用mysql的内置函数,索引失效。
-
对索引列运算(如,+、-、*、/),索引失效。
-
索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
-
索引字段上使用is null, is not null,可能导致索引失效。
-
左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
-
mysql估计使用全表扫描要比使用索引快,则不使用索引。
索引不适合哪些场景
-
数据量少的不适合加索引
-
更新比较频繁的也不适合加索引
-
区分度低的字段不适合加索引(如性别)
索引的一些潜规则
-
覆盖索引
-
回表
-
索引数据结构(B+树)
-
最左前缀原则
-
索引下推
2. MySQL 遇到过死锁问题吗,你是如何解决的?
我排查死锁的一般步骤:
-
查看死锁日志show engine innodb status;
-
找出死锁Sql
-
分析sql加锁情况
-
模拟死锁案发
-
分析死锁日志
-
分析死锁结果
可以看我这两篇文章哈:
3. 日常工作中你是怎么优化SQL的?
可以从这几个维度回答这个问题:
-
加索引
-
避免返回不必要的数据
-
适当分批量进行
-
优化sql结构
-
分库分表
-
读写分离
可以看我这篇文章哈:
4. 说说分库与分表的设计
分库分表方案,分库分表中间件,分库分表可能遇到的问题
分库分表方案:
-
水平分库:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
-
水平分表:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
-
垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
-
垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
常用的分库分表中间件:
-
sharding-jdbc(当当)
-
Mycat
-
TDDL(淘宝)
-
Oceanus(58同城数据库中间件)
-
vitess(谷歌开发的数据库中间件)
-
Atlas(Qihoo 360)
分库分表可能遇到的问题
-
事务问题:需要用分布式事务啦
-
跨节点Join的问题:解决这一问题可以分两次查询实现
-
跨节点的count,order by,group by以及聚合函数问题:分别在各个节点上得到结果后在应用程序端进行合并。
-
数据迁移,容量规划,扩容等问题
-
ID问题:数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑UUID
-
跨分片的排序分页问题(后台加大pagesize处理?)
5. InnoDB与MyISAM的区别
-
InnoDB支持事务,MyISAM不支持事务
-
InnoDB支持外键,MyISAM不支持外键
-
InnoDB 支持 MVCC(多版本并发控制),MyISAM 不支持
-
select count(*) from table时,MyISAM更快,因为它有一个变量保存了整个表的总行数,可以直接读取,InnoDB就需要全表扫描。
-
Innodb不支持全文索引,而MyISAM支持全文索引(5.7以后的InnoDB也支持全文索引)
-
InnoDB支持表、行级锁,而MyISAM支持表级锁。
-
InnoDB表必须有主键,而MyISAM可以没有主键
-
Innodb表需要更多的内存和存储,而MyISAM可被压缩,存储空间较小,。
-
Innodb按主键大小有序插入,MyISAM记录插入顺序是,按记录插入顺序保存。
-
InnoDB 存储引擎提供了具有提交、回滚、崩溃恢复能力的事务安全,与 MyISAM 比 InnoDB 写的效率差一些,并且会占用更多的磁盘空间以保留数据和索引
6. 数据库索引的原理,为什么要用 B+树,为什么不用二叉树?
可以从几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,以及查找磁盘次数,为什么不是二叉树,为什么不是平衡二叉树,为什么不是B树,而偏偏是B+树呢?
为什么不是一般二叉树?
如果二叉树特殊化为一个链表,相当于全表扫描。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
为什么不是平衡二叉树呢?
我们知道,在内存比在磁盘的数据,查询效率快得多。如果树这种数据结构作为索引,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果是B树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数就降下来啦,查询效率就快啦。
那为什么不是B树而是B+树呢?
1)B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。innodb中页的默认大小是16KB,如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。
2)B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,链表连着的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。
可以看这篇文章哈:
再有人问你为什么MySQL用B+树做索引,就把这篇文章发给她
7. 聚集索引与非聚集索引的区别
-
一个表中只能拥有一个聚集索引,而非聚集索引一个表可以存在多个。
-
聚集索引,索引中键值的逻辑顺序决定了表中相应行的物理顺序;非聚集索引,索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
-
索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
-
聚集索引:物理存储按照索引排序;非聚集索引:物理存储不按照索引排序;
何时使用聚集索引或非聚集索引?

8. limit 1000000 加载很慢的话,你是怎么解决的呢?
方案一:如果id是连续的,可以这样,返回上次查询的最大记录(偏移量),再往下limit
select id,name from employee where id>1000000 limit 10.
方案二:在业务允许的情况下限制页数:
建议跟业务讨论,有没有必要查这么后的分页啦。因为绝大多数用户都不会往后翻太多页。
方案三:order by + 索引(id为索引)
select id,name from employee order by id limit 1000000,10
方案四:利用延迟关联或者子查询优化超多分页场景。(先快速定位需要获取的id段,然后再关联)
SELECT a.* FROM employee a, (select id from employee where 条件 LIMIT 1000000,10 ) b where a.id=b.id
9. 如何选择合适的分布式主键方案呢?
-
数据库自增长序列或字段。
-
UUID。
-
Redis生成ID
-
Twitter的snowflake算法
-
利用zookeeper生成唯一ID
-
MongoDB的ObjectId
10. 事务的隔离级别有哪些?MySQL的默认隔离级别是什么?
-
读未提交(Read Uncommitted)
-
读已提交(Read Committed)
-
可重复读(Repeatable Read)
-
串行化(Serializable)
Mysql默认的事务隔离级别是可重复读(Repeatable Read)
可以看我这篇文章哈:一文彻底读懂MySQL事务的四大隔离级别
11. SQL优化的一般步骤是什么,怎么看执行计划(explain),如何理解其中各个字段的含义。
-
show status 命令了解各种 sql 的执行频率
-
通过慢查询日志定位那些执行效率较低的 sql 语句
-
explain 分析低效 sql 的执行计划(这点非常重要,日常开发中用它分析Sql,会大大降低Sql导致的线上事故)
看过这篇文章,觉得很不错:
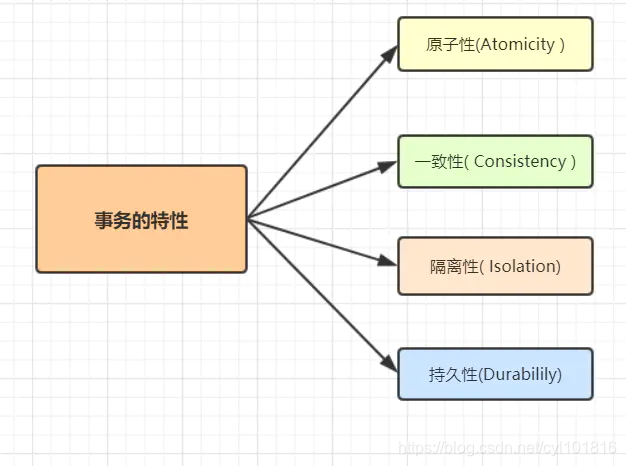
12. MySQL事务得四大特性以及实现原理
-
原子性: 事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
-
一致性: 指在事务开始之前和事务结束以后,数据不会被破坏,假如A账户给B账户转10块钱,不管成功与否,A和B的总金额是不变的。
-
隔离性: 多个事务并发访问时,事务之间是相互隔离的,即一个事务不影响其它事务运行效果。简言之,就是事务之间是进水不犯河水的。
-
持久性: 表示事务完成以后,该事务对数据库所作的操作更改,将持久地保存在数据库之中。
事务ACID特性的实现思想
-
原子性:是使用 undo log来实现的,如果事务执行过程中出错或者用户执行了rollback,系统通过undo log日志返回事务开始的状态。
-
持久性:使用 redo log来实现,只要redo log日志持久化了,当系统崩溃,即可通过redo log把数据恢复。
-
隔离性:通过锁以及MVCC,使事务相互隔离开。
-
一致性:通过回滚、恢复,以及并发情况下的隔离性,从而实现一致性。
13. 如果某个表有近千万数据,CRUD比较慢,如何优化。
分库分表
某个表有近千万数据,可以考虑优化表结构,分表(水平分表,垂直分表),当然,你这样回答,需要准备好面试官问你的分库分表相关问题呀,如
-
分表方案(水平分表,垂直分表,切分规则hash等)
-
分库分表中间件(Mycat,sharding-jdbc等)
-
分库分表一些问题(事务问题?跨节点Join的问题)
-
解决方案(分布式事务等)
索引优化
除了分库分表,优化表结构,当然还有所以索引优化等方案~
有兴趣可以看我这篇文章哈~
14. 数据库自增主键可能遇到什么问题。
-
使用自增主键对数据库做分库分表,可能出现诸如主键重复等的问题。解决方案的话,简单点的话可以考虑使用UUID哈
-
自增主键会产生表锁,从而引发问题
-
自增主键可能用完问题。
15. MVCC熟悉吗,它的底层原理?
MVCC,多版本并发控制,它是通过读取历史版本的数据,来降低并发事务冲突,从而提高并发性能的一种机制。
MVCC需要关注这几个知识点:
-
事务版本号
-
表的隐藏列
-
undo log
-
read view
可以看我这篇文章哈:一文彻底读懂MySQL事务的四大隔离级别
16. 数据库中间件了解过吗,sharding jdbc,mycat?
-
sharding-jdbc目前是基于jdbc驱动,无需额外的proxy,因此也无需关注proxy本身的高可用。
-
Mycat 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库,而 Sharding-JDBC 是基于 JDBC 接口的扩展,是以 jar 包的形式提供轻量级服务的。
有网友推荐这篇文章:
深度认识Sharding-JDBC:做最轻量级的数据库中间层
17. MYSQL的主从延迟,你怎么解决?
嘻嘻,先复习一下主从复制原理吧,如图:
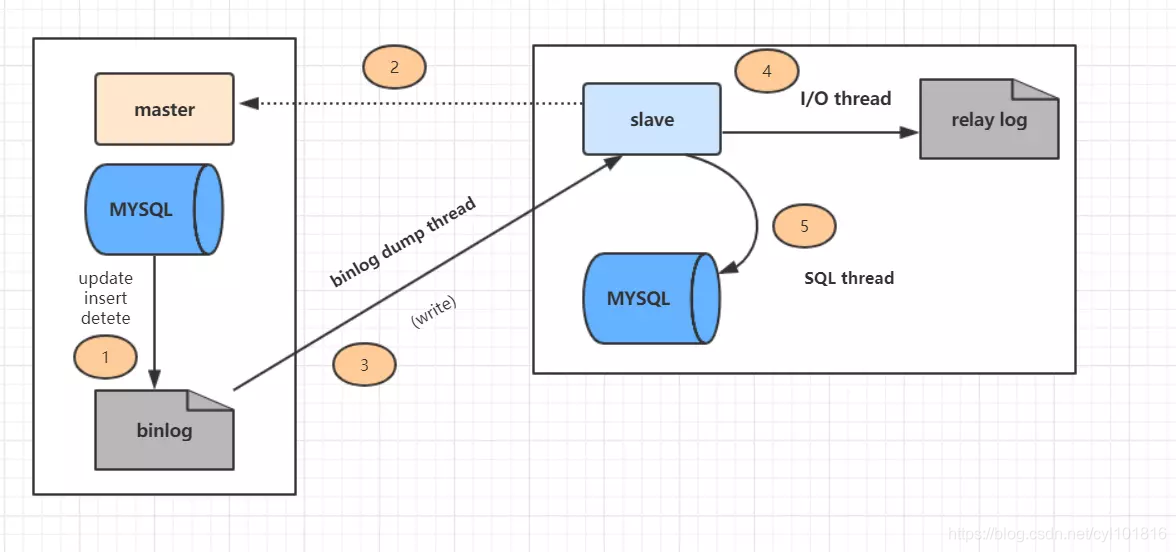
主从复制分了五个步骤进行:
-
步骤一:主库的更新事件(update、insert、delete)被写到binlog
-
步骤二:从库发起连接,连接到主库。
-
步骤三:此时主库创建一个binlog dump thread,把binlog的内容发送到从库。
-
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
-
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
有兴趣的小伙伴也可以看看我这篇文章:
主从同步延迟的原因
一个服务器开放N个链接给客户端来连接的,这样有会有大并发的更新操作, 但是从服务器的里面读取binlog的线程仅有一个,当某个SQL在从服务器上执行的时间稍长 或者由于某个SQL要进行锁表就会导致,主服务器的SQL大量积压,未被同步到从服务器里。这就导致了主从不一致, 也就是主从延迟。
主从同步延迟的解决办法
-
主服务器要负责更新操作,对安全性的要求比从服务器要高,所以有些设置参数可以修改,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置等。
-
选择更好的硬件设备作为slave。
-
把一台从服务器当度作为备份使用, 而不提供查询, 那边他的负载下来了, 执行relay log 里面的SQL效率自然就高了。
-
增加从服务器喽,这个目的还是分散读的压力,从而降低服务器负载。
可以看这篇文章哈~
18. 说一下大表查询的优化方案
-
优化shema、sql语句+索引;
-
可以考虑加缓存,memcached, redis,或者JVM本地缓存;
-
主从复制,读写分离;
-
分库分表;
20. 一条SQL语句在MySQL中如何执行的?
先看一下Mysql的逻辑架构图吧~

查询语句:
-
先检查该语句是否有权限
-
如果没有权限,直接返回错误信息
-
如果有权限,在 MySQL8.0 版本以前,会先查询缓存。
-
如果没有缓存,分析器进行词法分析,提取 sql 语句select等的关键元素。然后判断sql 语句是否有语法错误,比如关键词是否正确等等。
-
优化器进行确定执行方案
-
进行权限校验,如果没有权限就直接返回错误信息,如果有权限就会调用数据库引擎接口,返回执行结果。
这篇文章非常不错,大家去看一下吧:
21. InnoDB引擎中的索引策略,了解过吗?
-
覆盖索引
-
最左前缀原则
-
索引下推
索引下推优化是 MySQL 5.6 引入的, 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
这篇文章非常不错,大家去看一下吧:
22. 一条sql执行过长的时间,你如何优化,从哪些方面入手?
-
查看是否涉及多表和子查询,优化Sql结构,如去除冗余字段,是否可拆表等
-
优化索引结构,看是否可以适当添加索引
-
数量大的表,可以考虑进行分离/分表(如交易流水表)
-
数据库主从分离,读写分离
-
explain分析sql语句,查看执行计划,优化sql
-
查看mysql执行日志,分析是否有其他方面的问题
24. mysql 的内连接、左连接、右连接有什么区别?
-
Inner join 内连接,在两张表进行连接查询时,只保留两张表中完全匹配的结果集
-
left join 在两张表进行连接查询时,会返回左表所有的行,即使在右表中没有匹配的记录。
-
right join 在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录。
25. 说一下数据库的三大范式
-
第一范式:数据表中的每一列(每个字段)都不可以再拆分。
-
第二范式:在第一范式的基础上,分主键列完全依赖于主键,而不能是依赖于主键的一部分。
-
第三范式:在满足第二范式的基础上,表中的非主键只依赖于主键,而不依赖于其他非主键。
26. mysql有关权限的表有哪几个呢?
MySQL服务器通过权限表来控制用户对数据库的访问,权限表存放在mysql数据库里,由mysql_install_db脚本初始化。这些权限表分别user,db,table_priv,columns_priv和host。
-
user权限表:记录允许连接到服务器的用户帐号信息,里面的权限是全局级的。
-
db权限表:记录各个帐号在各个数据库上的操作权限。
-
table_priv权限表:记录数据表级的操作权限。
-
columns_priv权限表:记录数据列级的操作权限。
-
host权限表:配合db权限表对给定主机上数据库级操作权限作更细致的控制。这个权限表不受GRANT和REVOKE语句的影响。
27. InnoDB引擎的4大特性,了解过吗
-
插入缓冲(insert buffer)
-
二次写(double write)
-
自适应哈希索引(ahi)
-
预读(read ahead)
28. 索引有哪些优缺点?
优点:
-
唯一索引可以保证数据库表中每一行的数据的唯一性
-
索引可以加快数据查询速度,减少查询时间
缺点:
-
创建索引和维护索引要耗费时间
-
索引需要占物理空间,除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间
-
以表中的数据进行增、删、改的时候,索引也要动态的维护。
29. 索引有哪几种类型?
-
主键索引: 数据列不允许重复,不允许为NULL,一个表只能有一个主键。
-
唯一索引: 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
-
普通索引: 基本的索引类型,没有唯一性的限制,允许为NULL值。
-
全文索引:是目前搜索引擎使用的一种关键技术,对文本的内容进行分词、搜索。
-
覆盖索引:查询列要被所建的索引覆盖,不必读取数据行
-
组合索引:多列值组成一个索引,用于组合搜索,效率大于索引合并
30. 创建索引有什么原则呢?
-
最左前缀匹配原则
-
频繁作为查询条件的字段才去创建索引
-
频繁更新的字段不适合创建索引
-
索引列不能参与计算,不能有函数操作
-
优先考虑扩展索引,而不是新建索引,避免不必要的索引
-
在order by或者group by子句中,创建索引需要注意顺序
-
区分度低的数据列不适合做索引列(如性别)
-
定义有外键的数据列一定要建立索引。
-
对于定义为text、image数据类型的列不要建立索引。
-
删除不再使用或者很少使用的索引
31. 创建索引的三种方式
-
在执行CREATE TABLE时创建索引
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`date` datetime DEFAULT NULL,
`sex` int(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-
使用ALTER TABLE命令添加索引
ALTER TABLE table_name ADD INDEX index_name (column);
-
使用CREATE INDEX命令创建
CREATE INDEX index_name ON table_name (column);
32. 百万级别或以上的数据,你是如何删除的?
-
我们想要删除百万数据的时候可以先删除索引
-
然后批量删除其中无用数据
-
删除完成后重新创建索引。
33. 什么是最左前缀原则?什么是最左匹配原则?
最左前缀原则,就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
当我们创建一个组合索引的时候,如(k1,k2,k3),相当于创建了(k1)、(k1,k2)和(k1,k2,k3)三个索引,这就是最左匹配原则。
34. B树和B+树的区别,数据库为什么使用B+树而不是B树?
-
在B树中,键和值即存放在内部节点又存放在叶子节点;在B+树中,内部节点只存键,叶子节点则同时存放键和值。
-
B+树的叶子节点有一条链相连,而B树的叶子节点各自独立的。
B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,链表连着的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。.
B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。innodb中页的默认大小是16KB,如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快.
35. 覆盖索引、回表等这些,了解过吗?
-
覆盖索引: 查询列要被所建的索引覆盖,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
-
回表:二级索引无法直接查询所有列的数据,所以通过二级索引查询到聚簇索引后,再查询到想要的数据,这种通过二级索引查询出来的过程,就叫做回表。
网上这篇文章讲得很清晰:
36. B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据?
在B+树的索引中,叶子节点可能存储了当前的key值,也可能存储了当前的key值以及整行的数据,这就是聚簇索引和非聚簇索引。 在InnoDB中,只有主键索引是聚簇索引,如果没有主键,则挑选一个唯一键建立聚簇索引。如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
当查询使用聚簇索引时,在对应的叶子节点,可以获取到整行数据,因此不用再次进行回表查询。
37. 何时使用聚簇索引与非聚簇索引

38. 非聚簇索引一定会回表查询吗?
不一定,如果查询语句的字段全部命中了索引,那么就不必再进行回表查询(哈哈,覆盖索引就是这么回事)。
39. SQL的生命周期?
服务器与数据库建立连接
数据库进程拿到请求sql
解析并生成执行计划,执行
读取数据到内存,并进行逻辑处理
通过步骤一的连接,发送结果到客户端
关掉连接,释放资源
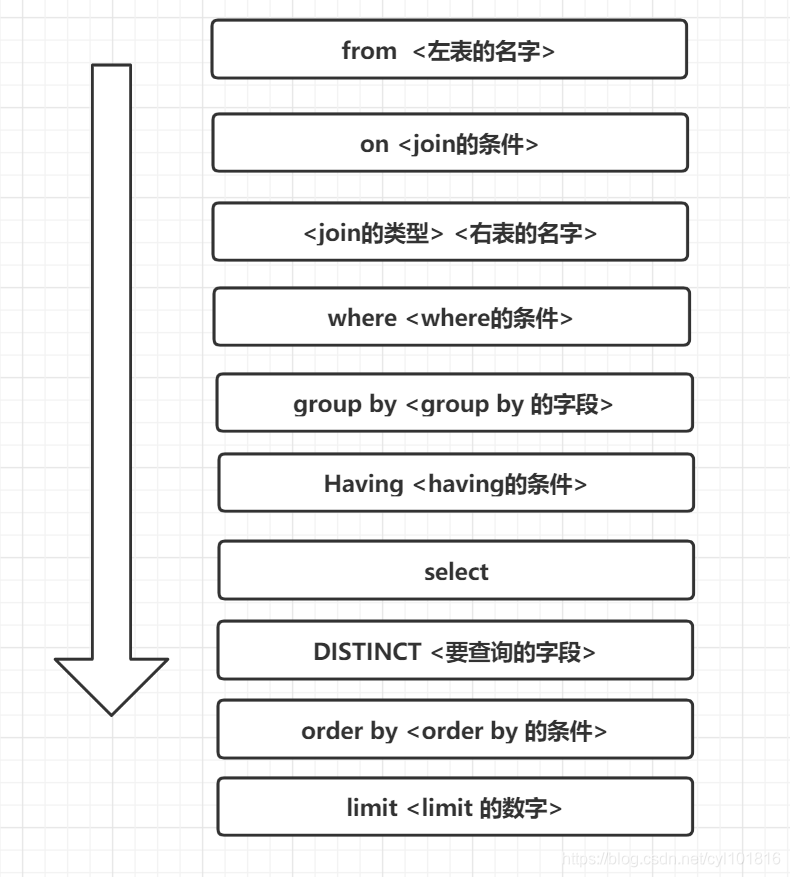
40. 一条Sql的执行顺序?
41. 主键使用自增ID还是UUID,为什么?
如果是单机的话,选择自增ID;如果是分布式系统,优先考虑UUID吧,但还是最好自己公司有一套分布式唯一ID生产方案吧。
-
自增ID:数据存储空间小,查询效率高。但是如果数据量过大,会超出自增长的值范围,多库合并,也有可能有问题。
-
uuid:适合大量数据的插入和更新操作,但是它无序的,插入数据效率慢,占用空间大。
42. MySQL的复制原理以及流程
主从复制原理,简言之,就三步曲,如下:
-
主数据库有个bin-log二进制文件,纪录了所有增删改Sql语句。(binlog线程)
-
从数据库把主数据库的bin-log文件的sql语句复制过来。(io线程)
-
从数据库的relay-log重做日志文件中再执行一次这些sql语句。(Sql执行线程)
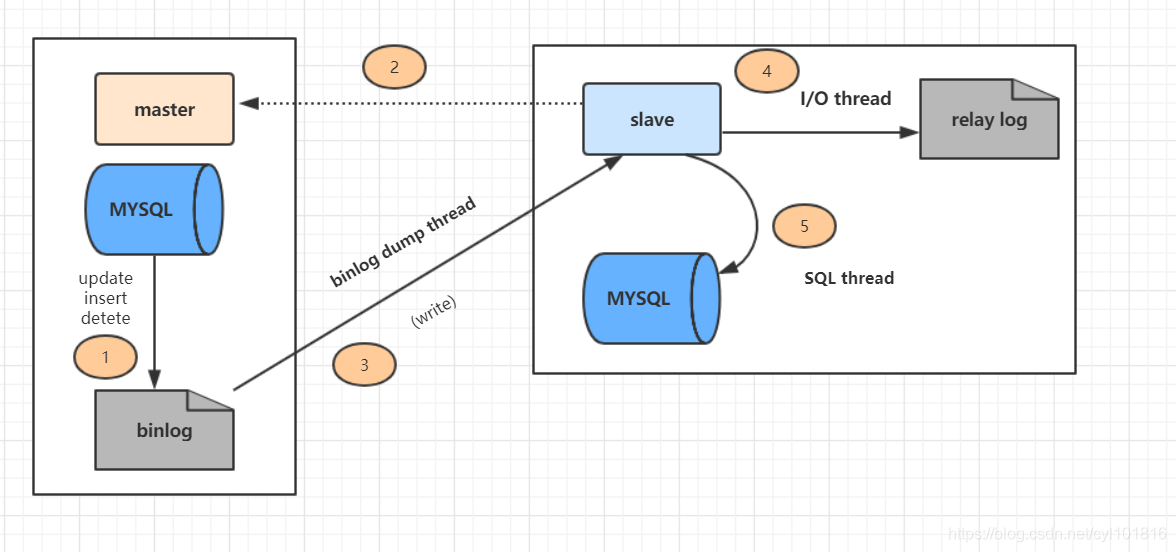
如下图所示:
上图主从复制分了五个步骤进行:
步骤一:主库的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库。
步骤三:此时主库创建一个binlog dump thread,把binlog的内容发送到从库。
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
43. Innodb的事务实现原理?
-
原子性:是使用 undo log来实现的,如果事务执行过程中出错或者用户执行了rollback,系统通过undo log日志返回事务开始的状态。
-
持久性:使用 redo log来实现,只要redo log日志持久化了,当系统崩溃,即可通过redo log把数据恢复。
-
隔离性:通过锁以及MVCC,使事务相互隔离开。
-
一致性:通过回滚、恢复,以及并发情况下的隔离性,从而实现一致性。
44. 谈谈MySQL的Explain
Explain 执行计划包含字段信息如下:分别是 id、select_type、table、partitions、type、possible_keys、key、key_len、ref、rows、filtered、Extra 等12个字段。
我们重点关注的是type,它的属性排序如下:
system > const > eq_ref > ref > ref_or_null >
index_merge > unique_subquery > index_subquery >
range > index > ALL
推荐大家看这篇文章哈:
面试官:不会看 Explain执行计划,简历敢写 SQL 优化?
45. Innodb的事务与日志的实现方式
有多少种日志
innodb两种日志redo和undo。
日志的存放形式
-
redo:在页修改的时候,先写到 redo log buffer 里面, 然后写到 redo log 的文件系统缓存里面(fwrite),然后再同步到磁盘文件( fsync)。
-
Undo:在 MySQL5.5 之前, undo 只能存放在 ibdata文件里面, 5.6 之后,可以通过设置 innodb_undo_tablespaces 参数把 undo log 存放在 ibdata之外。
事务是如何通过日志来实现的
-
因为事务在修改页时,要先记 undo,在记 undo 之前要记 undo 的 redo, 然后修改数据页,再记数据页修改的 redo。 Redo(里面包括 undo 的修改) 一定要比数据页先持久化到磁盘。
-
当事务需要回滚时,因为有 undo,可以把数据页回滚到前镜像的 状态,崩溃恢复时,如果 redo log 中事务没有对应的 commit 记录,那么需要用 undo把该事务的修改回滚到事务开始之前。
-
如果有 commit 记录,就用 redo 前滚到该事务完成时并提交掉。















 2150
2150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









