







原文网址:MySQL索引系列--聚集索引/辅助索引/回表查询/覆盖索引(原理及优化)_IT利刃出鞘的博客-CSDN博客
简介
本文介绍如下内容:聚集索引;辅助索引;什么是回表查询,如何优化回表查询;什么是覆盖索引,覆盖索引的应用场景等。
表结构和数据
为了便于展示概念,本处先建好一个用户表(t_user),表建好后是这样的:
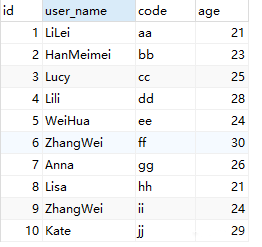
语句
DROP DATABASE IF EXISTS demo;
CREATE DATABASE demo DEFAULT CHARACTER SET utf8;
USE demo;
DROP TABLE IF EXISTS t_user;
CREATE TABLE `t_user`
(
`id` BIGINT(0) AUTO_INCREMENT,
`user_name` VARCHAR(64),
`code` VARCHAR(20),
`age` INT,
PRIMARY KEY (`id`),
KEY index_user_name (`user_name`),
KEY index_code (`code`)
) ENGINE = InnoDB;
INSERT INTO `t_user` VALUES (1, 'LiLei', 'aa', 21);
INSERT INTO `t_user` VALUES (2, 'HanMeimei', 'bb', 23);
INSERT INTO `t_user` VALUES (3, 'Lucy', 'cc', 25);
INSERT INTO `t_user` VALUES (4, 'Lili', 'dd', 28);
INSERT INTO `t_user` VALUES (5, 'WeiHua', 'ee', 24);
INSERT INTO `t_user` VALUES (6, 'ZhangWei', 'ff', 30);
INSERT INTO `t_user` VALUES (7, 'Anna', 'gg', 26);
INSERT INTO `t_user` VALUES (8, 'Lisa', 'hh', 21);
INSERT INTO `t_user` VALUES (9, 'ZhangWei', 'ii', 24);
INSERT INTO `t_user` VALUES (10, 'Kate', 'jj', 29);
聚集索引和辅助索引
在介绍回表和覆盖索引之前,需要先介绍聚集索引和辅助索引。
InnoDB有两大类索引:聚集索引(Clustered Index)和辅助索引(Secondary Index)。
| 项 | 聚集索引 | 辅助索引 |
| 别名 | 聚簇索引 | 二级索引、普通索引、非聚集索引、非聚簇索引 |
| 结构 | 叶子页保存了整个行数据。 所以也将聚集索引的叶子节点称为数据页。 | 叶子节点只存储聚集索引的非叶子节点存储的值(一般是主键ID)。 想拿到行数据,要根据主键去聚集索引取行数据。 |
| 数量 | 一张表必须有且只有一个聚集索引。 | 一张表可以有任意个普通索引。(没有也可以) |
| 优点 | 基于主键的查询非常快。 因为直接定位行记录。 | 更新代价比聚集索引要小 |
| 缺点 | 1. 更新代价大(可忽略此缺点,因为主键一般不变) | 若需要回表,则速度慢。 (若覆盖索引,则速度快。) |
聚集索引
简介
对于本文用户表来说,聚集索引是这样的:

聚集索引的生成规则:
- 如果表定义了PK(Primary Key,主键),那么PK就是聚集索引。
- 如果表没有定义PK,则第一个NOT NULL UNIQUE的列就是聚集索引。
- 否则InnoDB会另外创建一个隐藏的ROWID作为聚集索引。
优点
基于主键的查询非常快。因为直接定位行记录。
缺点
- 更新代价大
- 如果对索引列的数据被修改时,那么对应的索引也将会被修改,可能涉及自旋操作维护平衡, 而且聚集索引的叶子节点还存放着数据,修改代价肯定是较大的, 所以对于主键索引来说,主键一般都是不可被修改的。
- 依赖于有序的数据
- 因为B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或UUID这种又长又难比较的数据,插入或查找的速度肯定比较慢。
辅助索引
简介
InnoDB辅助索引的叶子节点存储主键值。想拿到行数据,要根据主键去聚集索引取行数据。
上边只是部分内容,为便于维护,本文已迁移到此地址:MySQL-聚集索引/辅助索引/回表查询/覆盖索引(原理及优化) - 自学精灵
















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











