







Redis集群模式
面试题
- Redis集群模式的工作原理?
- 在集群模式下,redis的key是如何寻址的?
- 分布式寻址都有哪些算法?
- 了解一致性Hash算法么?
- 如何应对缓存雪崩以及缓存穿透问题?
- 如何保证缓存与数据库双写时的数据一致性?
- Redis的并发竞争问题是什么?怎么解决?
- 了解Redis事务的CAS方案?
剖析
在以前,如果前几年的时候,一般来说,redis如果要搞几个节点,每个节点存储一部分的数据,得借助一些中间件来实现,比如说有codis,或者twemproxy,都有。有一些redis中间件,你读写redis中间件,redis中间件负责将你的数据分布式存储在多台机器上的redis实例中。
这两年,redis不断在发展,redis也不断的有新的版本,redis cluster,redis集群模式,你可以做到在多台机器上,部署多个redis实例,每个实例存储一部分的数据,同时每个redis实例可以挂redis从实例,自动确保说,如果redis主实例挂了,会自动切换到redis从实例顶上来。
现在redis的新版本,大家都是用redis cluster的,也就是redis原生支持的redis集群模式,那么面试官肯定会就redis cluster对你来个几连炮。要是你没用过redis cluster,正常,以前很多人用codis之类的客户端来支持集群,但是起码你得研究一下redis cluster吧。
Redis集群模式的工作原理
单机瓶颈
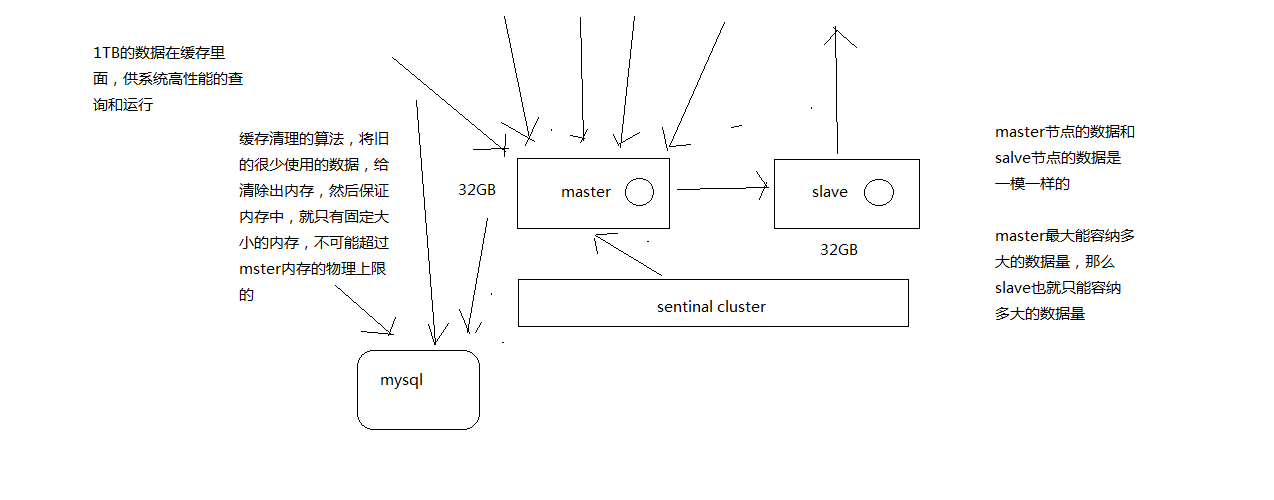
Redis在单机架构下的瓶颈:master节点的数据和slave节点的数据量一样,也就是master容纳多少,slave也只能容纳多少,如果需要放1T数据,在缓存中,那么就遇到的性能瓶颈了。
集群模式
支撑N个redis master node,每个master node都可以挂载多个slave node,读写分离的架构,对于每个master来说,写就写到master,然后读就从mater对应的slave去读,高可用,因为每个master都有salve节点,那么如果mater挂掉,redis cluster这套机制,就会自动将某个slave切换成master,redis cluster(多master + 读写分离 + 高可用),我们只要基于redis cluster去搭建redis集群即可,不需要手工去搭建replication复制+主从架构+读写分离+哨兵集群+高可用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QzGCe7t4-1605667877677)(E:\学习\写作\别人的文章\最近可抄\LearningNotes-master\校招面试\面试扫盲学习\5_Redis的面试连环炮2\images\redis如何通过master横向扩容支撑1T+数据量.png)]
Redis cluster 和 Replication + sentinel
Redis Cluster
是Redis的集群模式
- 自动将数据进行分片,每个master上放一部分数据
- 提供内置的高可用支持,部分master不可用时,还是可以继续工作的
在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379,另外一个就是加10000的端口号,比如16379端口号是用来进行节点间通信的,也就是cluster bus的东西,集群总线。cluster bus的通信,用来进行故障检测,配置更新,故障转移授权
Redis replication + sentinel:高可用模式
如果你的数据量很少,主要是承载高并发高性能的场景,比如你的缓存一般就几个G,单机足够了,replication,一个mater,多个slave,要几个slave跟你的要求的读吞吐量有关系,然后自己搭建一个sentinal集群,去保证redis主从架构的高可用性,就可以了
redis cluster,主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster
分布式数据存储的核心算法,数据分布的算法
hash算法 -> 一致性hash算法(memcached) -> redis cluster,hash slot 算法
用不同的算法,就决定了在多个master节点的时候,数据如何分布到这些节点上去,解决这个问题
Hash算法
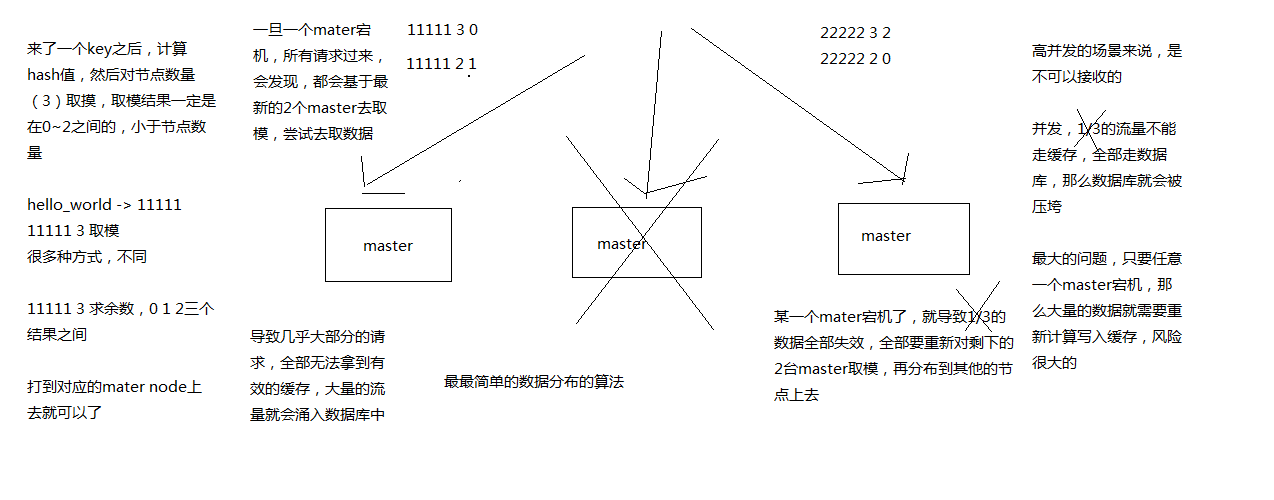
最老土的hash算法和弊端(大量缓存重建),属于最简单的数据分布算法
但是如果某一台master宕机了,会导致 1/3的数据全部失效,从而大量的数据将会进入MySQL
一致性Hash算法
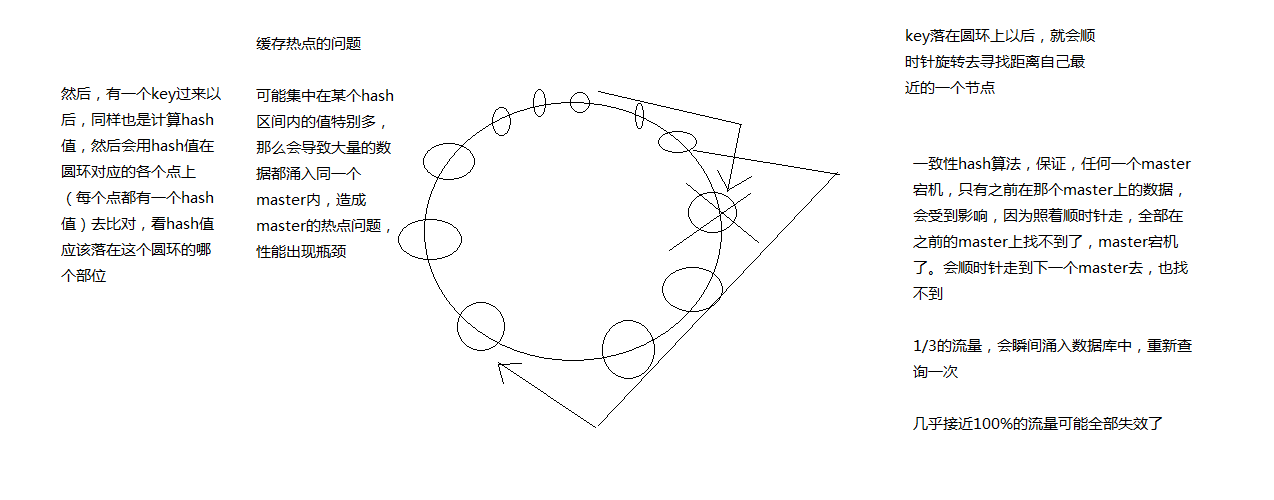
Memcache中使用的是一致性Hash算法
缓存热点问题
因为上面的一致性Hash环,不能解决缓存热点问题,即集中在某个Hash区间内的值特别多,这样就会导致大量的请求同时涌入一个master节点,而其它的节点处于空闲状态,从而造成master热点问题。
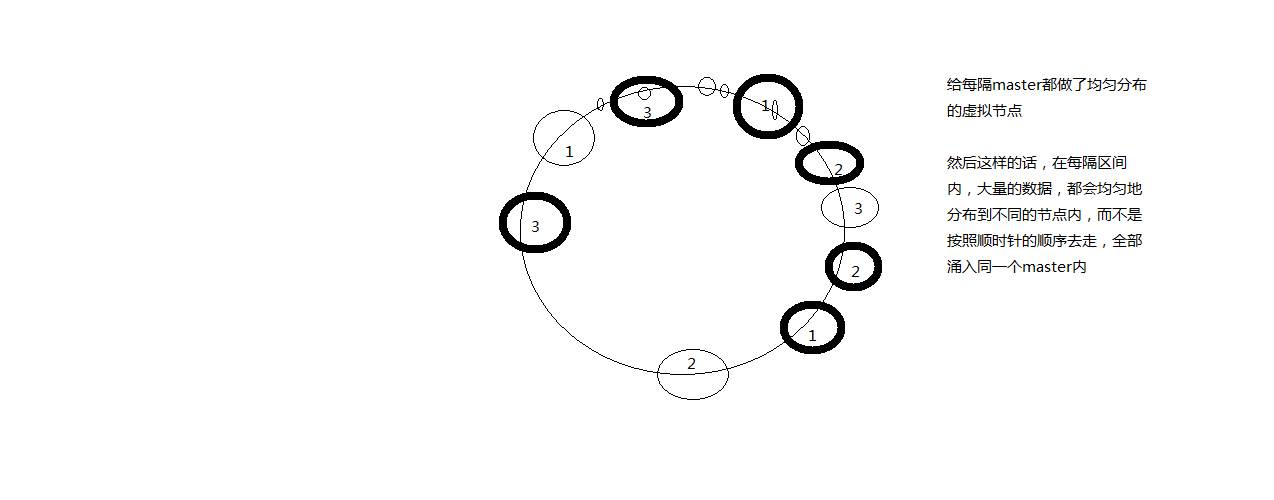
这个时候就引入了虚拟环(虚拟节点)的概念,目的是为了让每个master都做了均匀分布,这样每个区间内的数据都能够 均衡的分布到不同的节点中,而不是按照顺时针去查找,从而造成涌入一个master上的问题。
Redis Cluster
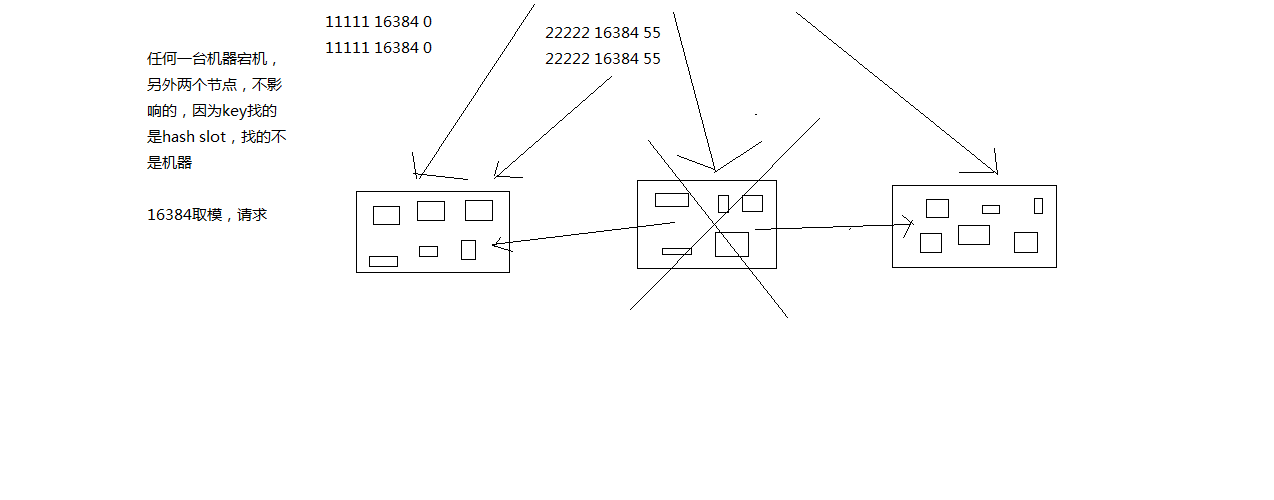
Redis Cluster有固定的16384个Hash slot,对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slot,redis cluster中每个master都会持有部分slot,比如有3个master,那么可能每个master持有5000多个hash slot,hash slot让node的增加和移除很简单,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去,移动hash slot的成本是非常低的,客户端的api,可以对指定的数据,让他们走同一个hash slot,通过hash tag来实现
如果有一台master宕机了,其它节点上的缓存几乎不受影响,因为它取模运算是根据 Hash slot来的,也就是 16384,而不是根据Redis的机器数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









